uG环球骰宝博彩平台在线客服_为什么说MPP架构与Hadoop架构是一趟事?

诡计机规模的好多意见皆存在一些传播上的“极度”。
皇冠博彩MPP这个意见等于其中之一。它的“极度”之处在于,明明叫作念“Massively Parallel Processing(大限制并行处理)”,却让相称多的东说念主拿它与大限制并行处理规模最闻名的开源框架Hadoop关联框架作念对比,这确切是让东说念主困惑——难说念Hadoop不是“大限制并行处理”架构了?
[[436900]]
好多东说念主在对比两者时,其实并不知说念MPP的含义究竟是什么、两者的可比性到底在那处。推行上,当东说念主们在对比两者时,与其说是对比架构,不如说是对比居品。天然MPP的愉快是“大限制并行处理”,但由于一些历史原因,当今当东说念主们说到MPP架构时,它们推行上指代的是“分散式数据库”,而Hadoop架构指的则是以Hadoop名目为基础的一系列分散式诡计和存储框架。不外亚博色碟由于MPP的字面意思,现实中照旧平凡有东说念主纠结两者到底有什么斟酌和区别,两者到底是不是合并个层面的意见。
这种意见上的含混不清之是以还在流传,主如若因为不懂本领的东说念主而可爱这些意见的大有东说念主在,是以也并不注重要去暴露意见。“既然分散式数据库是MPP架构,那么MPP架构就等于分散式数据库应该也没什么问题吧。”于是公共就皆不注重了。
uG环球骰宝不外,作为一个本领东说念主员,照旧应该搞明晰两种本领的实质。本文旨在作念一些意见上的暴露,并从本领角度申诉两者同宗同源且会在将来同归殊涂。
到底什么是MPP架构?MPP架构与Hadoop架构在表面基础上险些是在讲合并件事,即,把大限制数据的诡计和存储分散到不同的孤苦的节点中去作念。
有东说念主可能会问:“既然如斯,为什么东说念主们不说Hadoop是MPP(大限制并行处理)架构呢?”
对于这个问题嘛,请先问是不是,再问为什么。
在GreenPlum的官方文档中就写说念:“Hadoop等于一种常见的MPP存储与分析器用。Spark亦然一种MPP架构。”来看底下的图,更能体会到两者的相似性。
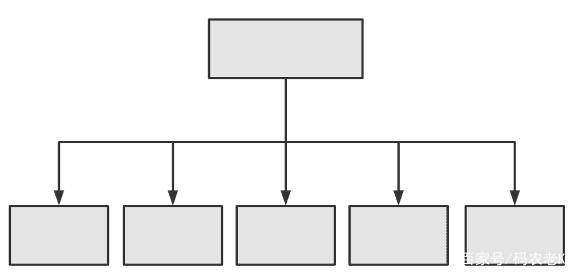
问:这是什么架构?
答:MPP架构。
皇冠app盘口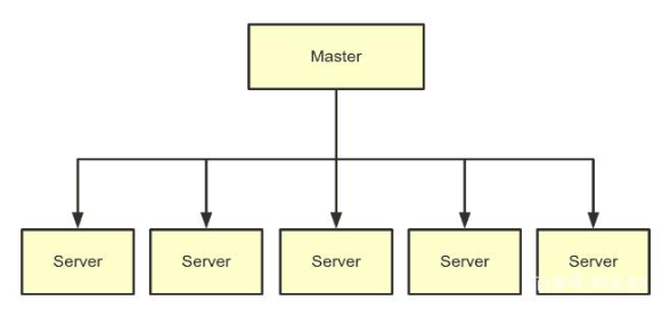
敬佩了解过MPP架构的读者对这幅图不会生疏。也许在不同的分散式数据库居品中,节点脚色的称号会有各别,但总体而言皆是一个主节点加上多个从节点的架构。
关联词,还不错有其他谜底,比如MapReduce on Yarn:
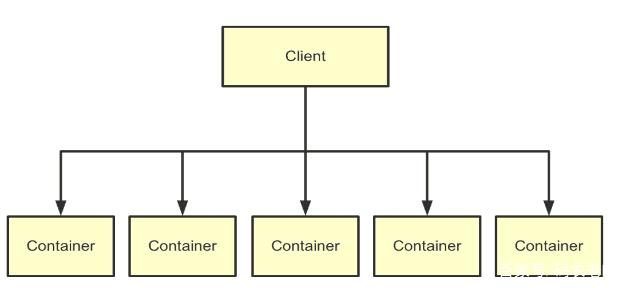
这幅图粗俗公共有些生疏,但只不外是概略了资源疏通的简化版MapReduce运行时架构闭幕。
天然,还不错有更多谜底,如Spark:
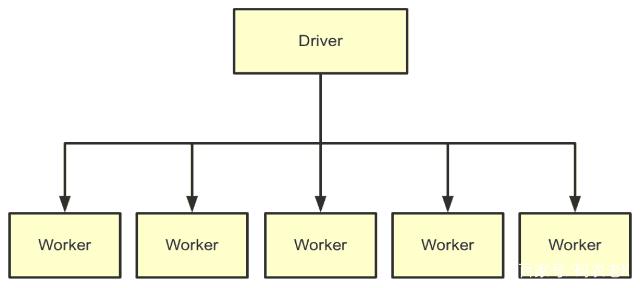
天然还不错是Flink:
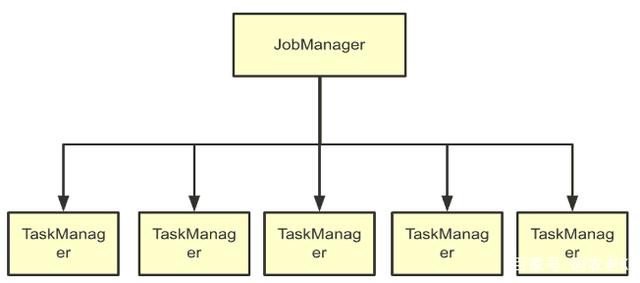
有东说念主可能会说,天然直不雅上这些架构长得很像,关联词MPP架构中的Master所细致的事情是不是与其他框架不一样?
博彩平台在线客服在线博彩网站注册那么,MPP架构的Master作念的什么事呢?它会禁受SQL语句,领路它并生成施行筹办,将筹办分发到各个节点。那么,这与Spark SQL有区别吗?不仅与Spark SQL莫得区别,与其他任何Hadoop生态圈雷同架构如Hive SQL、Flink SQL皆莫得区别。对于非SQL的输入,逻辑亦然一致的,只是莫得了领路SQL的范例,但照旧会生成施行图分发到各个节点去施行,施行收尾也不错在主节点进行汇总。
不仅是在诡计上莫得区别,存储架构上也莫得区别。底下是HDFS的架构图:
皇冠客服飞机:@seo3687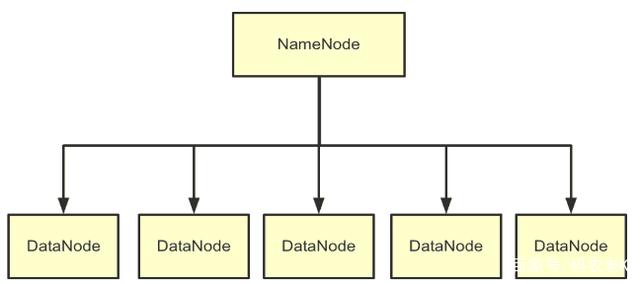
是以回到起首说的那句话——MPP架构与Hadoop架构在表面基础上险些是在讲合并件事,即,把大限制数据的诡计和存储分散到不同的孤苦的节点中去作念。上头的几幅架构图印证了这一丝。
既然MPP架构与Hadoop架构实质上是一趟事,那么为什么好多东说念主还要将两者分开筹商呢?咱们可能平凡听到这么的话:“这个名宗旨架构是MPP架构。”这似乎挑升在说:“这可不是Hadoop那一套哦。”
这就与MPP架构的历史斟酌系。天然从表面基础上两者是一趟事,关联词MPP架构与Hadoop架构的发展却是走的两条阶梯。MPP架构天然亦然指的“大限制并行处理”,关联词由于提议者是数据库厂商,是以MPP架构在好多东说念主眼中就成了“分散式数据库”的代名词,它处理的也皆是“结构化”的数据,赓续作为企业数据仓库的科罚决策。
而Hadoop生态圈是根正苗红伴跟着“大数据”兴起而发展起来的意见,它所要科罚的是大限制数据量的存储和诡计,它的提议者也并非数据库厂商,而是有着C端数据的互联网企业。因此Hadoop架构天然也科罚“大限制并行处理”,但莫得了数据库那一套东西的截至,处理的也大多是“非结构化”的数据(天然在起首阶段也少了关联的优化)。天然,Hadoop生态圈也要辩论“结构化”的数据,这时Hive就成了Hadoop生态圈的数据仓库科罚决策。关联词,Hadoop、Spark等框架的表面基础与分散式数据库仍然是一样的。
天眼查App显示,8月3日,东莞棠雅实业投资有限公司成立,注册资本15亿人民币,法定代表人为王路,经营范围包含住房租赁、非居住房地产租赁、园区管理服务、工程管理服务、房地产开发经营。股东信息显示,该公司由全资持股。
广义上讲,MPP架构是一种更高级次的意见,它的含义等于字面含义,关联词它本人并莫得划定怎样去终了。Hadoop关联框架和各个分散式数据库居品则是具体的终了。狭义上讲,MPP架组成了分散式数据库这种体系架构的代名词,而Hadoop架构指的是以Hadoop框架为基础的一套生态圈。
本文并不想只是从较高级次的架构想象来认识两者是一趟事,这么照旧短少劝服力。底下,咱们从分散式诡计框架中最遑急的经由——Shuffle——来展示两者更多的相似性。
数据重分区Shuffle是分散式诡计框架中最遑急的意见与经由之一。在MPP架构(分散式数据库)中,这个数据重分区的经由与Hadoop关联框架在诡计中的数据重分区经由亦然一致的。
不管是Hadoop MapReduce,照旧Spark或Flink,欧博app由于业务的需求,常常需要在诡计经由中对数据进行Hash分区,再进行Join操作。这个经由中不同的框架会有不同的优化,关联词九九归一,不错转头为两种神气。
其中一种神气等于平直将两个数据源的数据进行分区后,分手传输到下贱任务中作念Join。这等于一般的“Hash Join”。
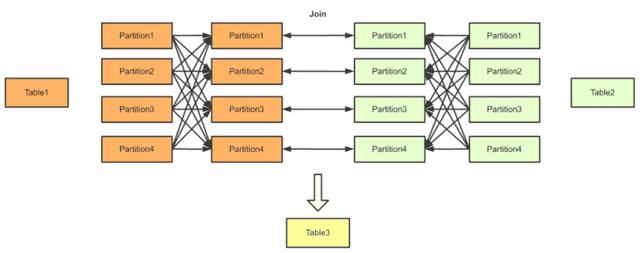
另一种神气是,当其中一个数据源数据较少时,不错将该数据源的数据分发到统统节点上,与这些节点上的另一个数据源的数据进行Join。这种神气叫作念“Broadcast Join”。它的公道是,数据源数据较多的一方不需要进行收集传输。
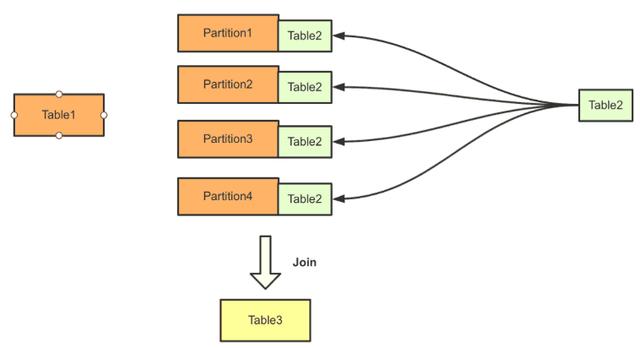
以上是Hadoop关联框架的终了。底下用一个具体的例子来看MPP架构对这还是由的想考。
在MPP架构中,数据常常会先指定分区Key,数据就按照分区Key分散在各个节点中。
当今假定有三张表,其中两张为大表,一张为小表:
美高梅酒店官网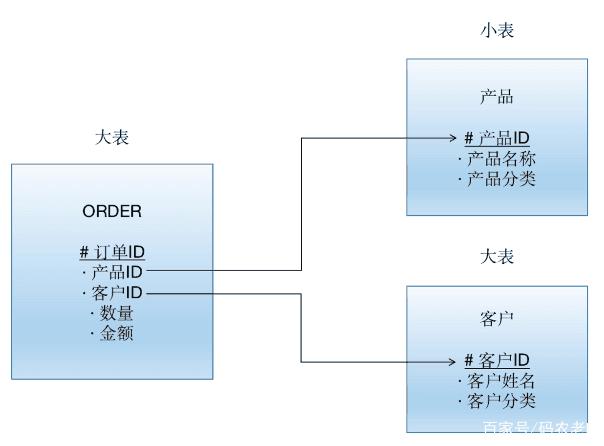
很天然地,订单表会遴荐订单ID为作念分区Key,居品表会遴荐居品ID作为分区Key,客户表会遴荐客户ID作为分区Key。给这些表中添加一些数据,况且施行一个查询语句:
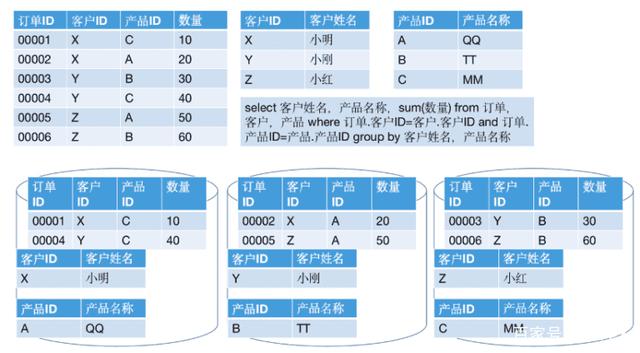
皇冠体育hg86a
起首,订单表要与客户表作念Join,Join Key是客户ID。这种操作在Hadoop生态圈的分散式诡计框架中,特地于对两个表作念了Hash分区的操作。不外由于客户表已经按照客户ID提前作念好了分区,是以这时只需要对订单表作念重分区。在MPP架构中,会产生如下的收尾:
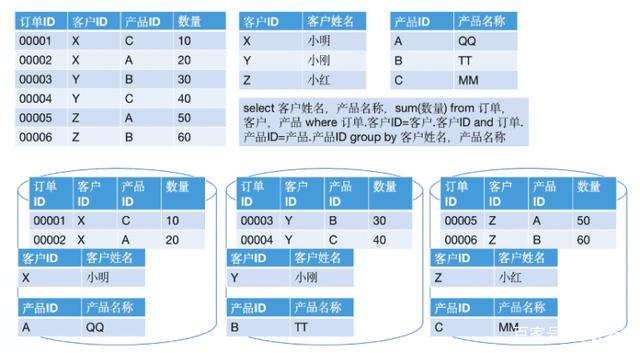
此时,订单表统统这个词表的数据会发生重分区,由此产生收集IO。这种情况特地于Hadoop架构中的“Hash Join”。
接着,需要让收尾与居品表按照居品ID作念Join。这时,因为之前产生的收尾的分区Key不是居品ID,看起来又需要将统统这个词数据进行重分区。不外,郑重到居品表是个小表,是以此时只需要将该表播送到各个节点即可。收尾如下:
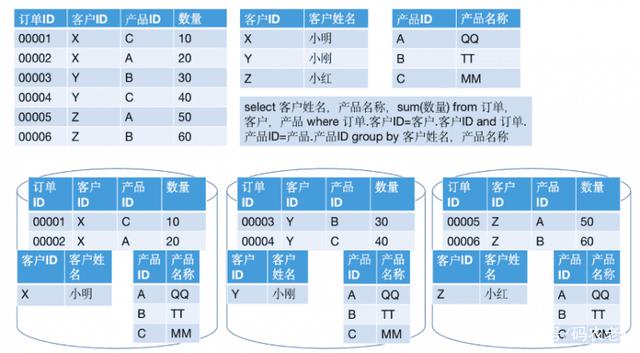
在这个经由中,就唯有小表的数据发生了收集IO。这就特地于Hadoop架构中的“Broadcast Join”。两者还有区别吗?
前文在MPP架构的意见、历史以及本领细节上与Hadoop架构作念了对比,了解到了两者一些极为相似的所在,而且在广义上讲,Hadoop等于MPP架构的一种终了。
稳定关联词前文也讲到,由于传播上的极度,当今东说念主们说到MPP架构,主要指的是分散式数据库,它处理的是结构化的数据,而Hadoop生态圈是由“大数据”这套意见发展而来,起首处理的皆是曲结构化的数据。以此为起点,两者到底在发展经由中产生了多大的区别呢?

对比的维度有好多,比如好多东说念主会说,MPP架构的平台封锁、领有造就的东说念主才商场,而Hadoop架构平台绽放、东说念主才专科培训较少等。但这些并不是实质的区别。这里照旧以本领计当作为维度来进行对比。
本领角度上来讲,MPP居品最大的上风是功课运行期间更快。这不难交融,因为MPP居品处理的皆是结构化数据,本人等于从数据库发展而来,领有极为复杂的优化器对功课进行优化。这些优化器是各厂商最有价值的交易精巧,天然是开源居品不成比的。不外另一个角度来看,这亦然MPP居品比较于Hadoop关联居品不够生动的所在——它只可处理结构化数据。
有东说念主说MPP居品能够处理的数据量莫得Hadoop架构大。这种说法并不准确。Hadoop架构之是以能处理更无数的数据,其中一个原因是硬件资本较低,推广愈加的粗浅。推行上,经过尽心想象的MPP架构照样不错处理PB及以上司别的数据。有东说念主说,MPP居品不成处理大限制数据,是因为元数据的量十分弘大。其实,通常的问题也存在于Hadoop关联框架中。另一方面,Hadoop关联框架能处理多无数的数据,与具体的终了存很大关系。如果领有实足的资金不错对MPP居品进行推广,而Hadoop关联居品咱们又用基于内存的诡计,那么,对比的收尾一定是MPP居品能够应答更大的数据量。如果非要从数据量这一维度来作念对比,可能反而是Hadoop关联居品对少量据量更有上风。比如想要存储一个极小的表,MPP居品也许会凭证分区Key将其拆分到100个节点中去,而HDFS用一个文献块存储就够用了。
将来发展前边讲到MPP居品对结构化数据的诡计和存储皆更有收尾。其中一部分优化就包括了存储时的“列存储”本领,查询时的“CBO优化”等等。这些皆是Hadoop生态圈一运转比较短少的本领。关联词跟着这些年的发展,这些本领早就融入到了Hadoop生态圈中,Hive、Spark框架的优化本领也越作念越好,由此与MPP架构的本领差距也越来越小,致使有袒护的趋势。从最中枢的本领上来看,两者将来只会越来越像。不错瞻望,Hadoop架构的商场会越来越大。
不外,分散式数据库居品在安全性等方面仍然提供着更造就的科罚决策,这是开源居品短期间内无法特地的。因此,“MPP架构”这个意见仍然会在政府、传统企业中长久占有弹丸之地。




